目标检测。YOLOv6的精度与速度都远超 YOLOv5 和 YOLOX。
生成人脸,编辑人脸。
给视频加字幕
文搜图,视频
阿里大模型开源
标注工具
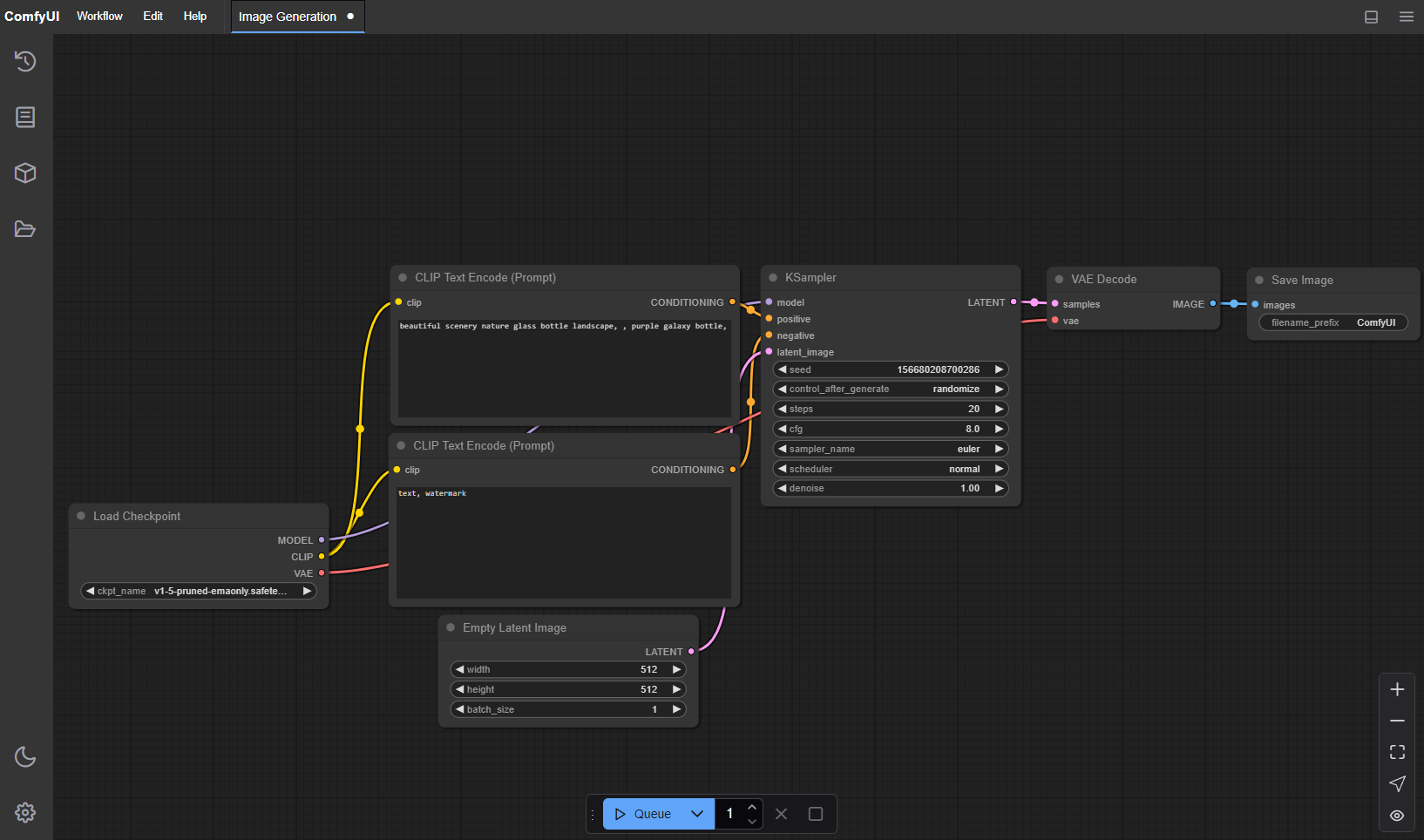
SD高级界面。ComfyUI 是一个基于节点流程式的stable diffusion AI 绘图工具WebUI。通过将stable diffusion的流程拆分成节点,实现了更加精准的工作流定制和完善的可复现性。但节点式的工作流也提高了一部分使用门槛。 同时,因为内部生成流程做了优化,生成图片时的速度相较于webui又10%~25%的提升(根据不同显卡提升幅度不同),生成大图片的时候不会爆显存,只是图片太大时,会因为切块运算的导致图片碎裂。