蛋白质结构。98.5%的人类蛋白质结构被Google AlphaFold2预测出来了! 而且还做成了数据集,全部免费开放!
医学图像数据集。MedMNIST v2 是一个大规模的 2D 和 3D 医学图像分类数据集,包含 12 个 2D 数据集和 6 个 3D 数据集,其中 2D 数据集有 708069 张图片,3D 数据集有 10214 张图片。数据集包含多种模态(X 光片、视网膜 OCT、超声、CT 等)、 多种任务(多分类、二分类、多标签、有序回归), 数据集规模从百量级到十万量级不等;
人脸识别。包含了来源于互联网的13233张来自5749个人的人脸图片,其中有1680个人至少有2张图片。
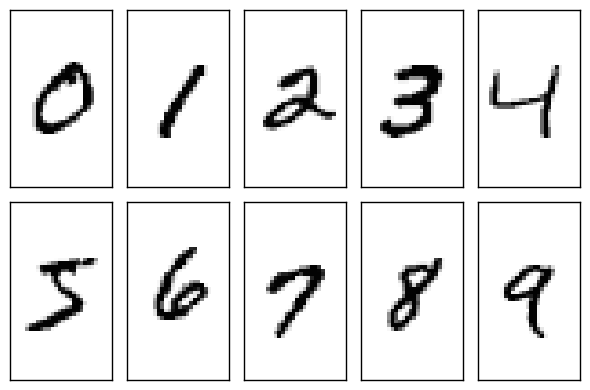
手写数字图片。训练集样本60,000个,测试集样本10,000个。由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局的工作人员。
超大图片集合。谷歌发布的图片数据库Open Images,包含了900万标注数据,标签种类超过6000种。谷歌在官方博客中写到,这比只拥有1000个分类的ImageNet 更加贴近实际生活。对于想要从零开始训练计算机视觉模型的人来说,这些数据远远足够了。
图像理解。为了使计算机理解图像,数据集中的图片被划分成一个个区域,每个区域都有与其对应的一句自然语言描述。共108,077张图。
32像素图片。CIFAR-10包含了10个种类的图片,包括飞机,汽车,鸟.....图片是彩色的。总共60,000个样本。CIFAR-100包含了100个种类,但是总共也只有60,000个样本。