场景图片。包含10个场景类别,例如卧室、固房、客厅、教室等场景图像。每类场景大约有120,000至3,000,000张图片。
检测图内中文。
水果蔬菜数据。包含90483张图,131个种类,100像素。
图像理解。为了使计算机理解图像,数据集中的图片被划分成一个个区域,每个区域都有与其对应的一句自然语言描述。共108,077张图。
城市街道场景。是关于城市街道场景的语义理解图片数据集。 它主要包含来自50个不同城市的街道场景,拥有5000张在城市环境中驾驶场景的高质量像素级注释图像。此外,它还有20000张粗糙标注的图像。
32像素图片。CIFAR-10包含了10个种类的图片,包括飞机,汽车,鸟.....图片是彩色的。总共60,000个样本。CIFAR-100包含了100个种类,但是总共也只有60,000个样本。
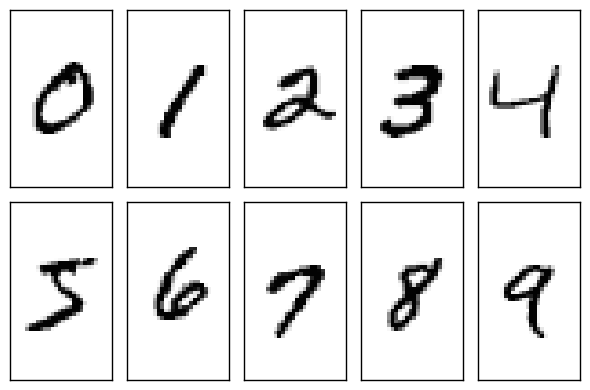
手写数字图片。训练集样本60,000个,测试集样本10,000个。由来自 250 个不同人手写的数字构成, 其中 50% 是高中学生, 50% 来自人口普查局的工作人员。